Abstract
Framework
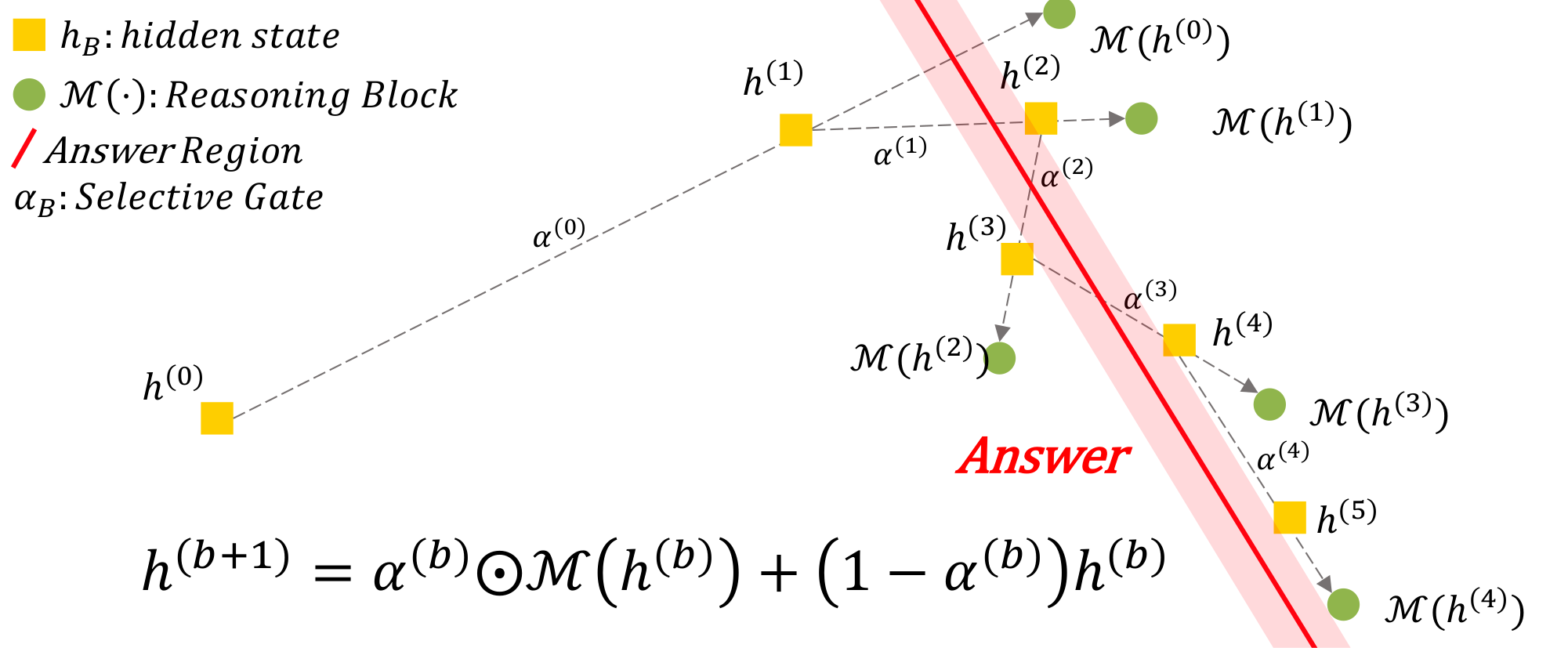
Figure 1: Conceptual view of latent refinement in LoopUS. As the reasoning block is looped, each proposed update is mixed with the previous hidden state by the selective gate, gradually steering the trajectory toward the answer region instead of allowing it to drift.
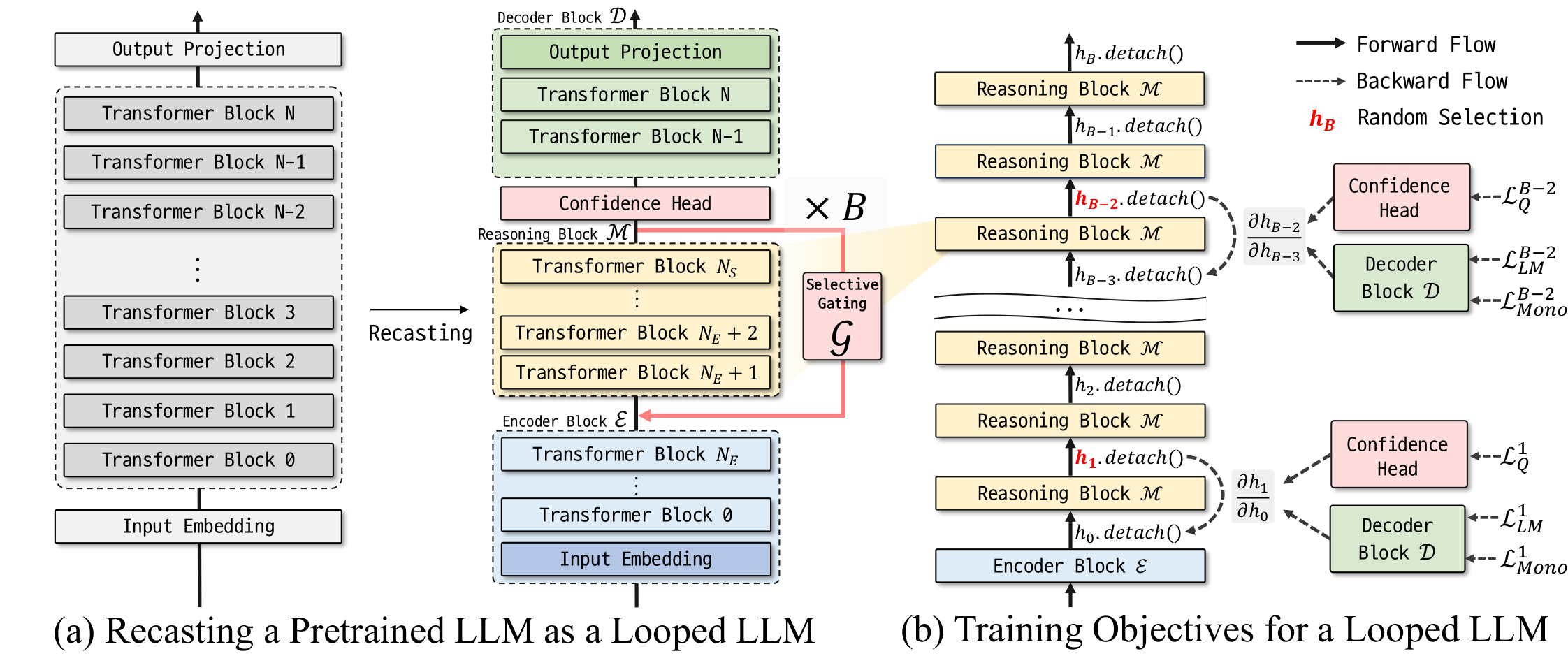
Figure 2: Overview of the LoopUS architecture. (a) A pretrained LLM is recast into encoder, reasoning, and decoder blocks, using a selective gate ($\mathcal{G}$) inserted between loop iterations to stabilize the loop dynamics. (b) The looped LLM is trained with random deep supervision using next-token prediction loss ($\mathcal{L}_{\mathrm{LM}}$), monotonicity loss ($\mathcal{L}_{\text{Mono}}$), and confidence loss ($\mathcal{L}_{\text{Q}}$).
Experiments
| Method | Base Model |
Train Tokens |
Setting | Task | AVG | Δ | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| ARC-E | ARC-C | HS | WG | PIQA | OBQA | ||||||
acc_n ↑ |
acc_n ↑ |
acc_n ↑ |
acc ↑ |
acc_n ↑ |
acc_n ↑ |
||||||
| Ours | TinyLlama 1.1B |
3B | Original | 47.1 | 25.1 | 42.2 | 53.4 | 66.8 | 24.2 | 43.1 | -- |
| Adapted | 53.0 | 29.6 | 55.5 | 57.9 | 69.8 | 30.6 | 49.4 | +6.3 | |||
| McLeish et al. | TinyLlama 1.1B-3T |
52B | Original | 55.7 | 31.0 | 59.1 | 58.9 | 73.0 | 35.0 | 52.1 | -- |
| Adapted | 58.6 | 35.6 | 45.1 | 57.6 | 66.4 | 32.2 | 49.3 | -2.9 | |||
| Bae et al. | TinyLlama 1.1B |
60B | Original | 44.7 | 23.2 | 42.2 | 53.4 | 66.8 | 29.2 | 43.3 | -- |
| Adapted | 49.9 | 26.2 | 48.8 | 54.1 | 68.6 | 32.8 | 46.7 | +3.5 | |||
LoopUS shows adaptation efficiency under a smaller training-token budget. All methods adapt a TinyLlama-based backbone; w/o and w/ LoopUS denote the checkpoint before and after adaptation, respectively. AVG is the unweighted mean over the six tasks, and Δ reports the change in AVG from Original to Adapted. Results for prior methods are taken from the corresponding papers.
| Model | Setting | Wiki | LAMBADA | MMLU | HS | ARC-E | ARC-C | PIQA | WG | OBQA | AVG | Δ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
ppl ↓ |
acc ↑ |
|||||||||||
| Qwen 1.7B | w/o LoopUS | 21 | 12.21 | 55.4 | 46.2 | 72.5 | 40.2 | 72.2 | 61.3 | 28 | 53.7 | -- |
| w/ LoopUS | 16.9 | 7.43 | 56.6 | 46.3 | 74.9 | 43.1 | 73.3 | 63.0 | 29.6 | 55.3 | +1.6 | |
| Qwen 4B | w/o LoopUS | 16.4 | 7.29 | 68.3 | 52.1 | 80.2 | 50.4 | 75.0 | 66.5 | 29.4 | 60.3 | -- |
| w/ LoopUS | 13.9 | 5.33 | 67.7 | 51.4 | 81.3 | 54.0 | 76.8 | 68.9 | 34.4 | 62.1 | +1.8 | |
| Qwen 8B | w/o LoopUS | 12.2 | 4.58 | 72.8 | 57.2 | 81.5 | 55.4 | 76.3 | 67.9 | 31.6 | 63.2 | -- |
| w/ LoopUS | 10.3 | 4.32 | 71.5 | 56.0 | 83.9 | 58.1 | 78.9 | 72.4 | 37.0 | 65.4 | +2.2 | |
| Phi-4 14B | w/o LoopUS | 9.59 | 4.03 | 76.9 | 63.1 | 81.3 | 55.8 | 80.7 | 77.0 | 34.0 | 67.0 | -- |
| w/ LoopUS | 7.75 | 3.49 | 77.5 | 60.58 | 83.5 | 57.7 | 81.8 | 77.5 | 41.8 | 68.6 | +1.7 | |
LoopUS improves pretrained backbones across scales. Results on language modeling and downstream benchmarks. ppl denotes perplexity (lower is better), and acc denotes accuracy (higher is better). AVG is the mean over the seven acc benchmarks, and Δ denotes the change in AVG from the original backbone (w/o LoopUS) to the adapted checkpoint (w/ LoopUS). Bold highlights the better result between the two variants of each backbone. All models are evaluated zero-shot.
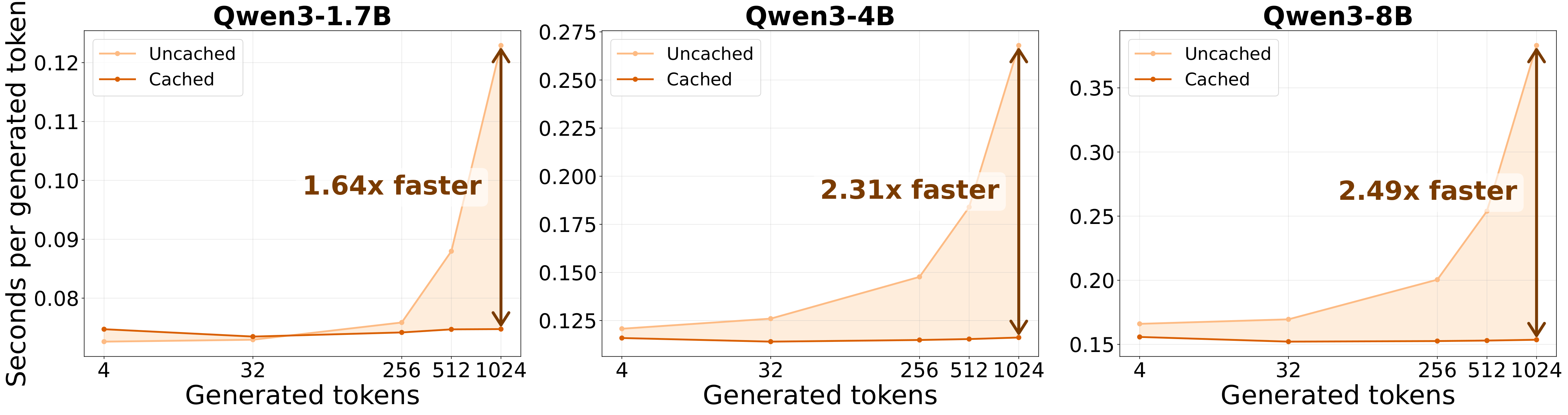
Figure 3: KV caching accelerates LoopUS decoding. With the recursion budget fixed to $B=8$, caching consistently reduces seconds per generated token across Qwen3-1.7B, Qwen3-4B, and Qwen3-8B, with the largest gains appearing at longer generations.
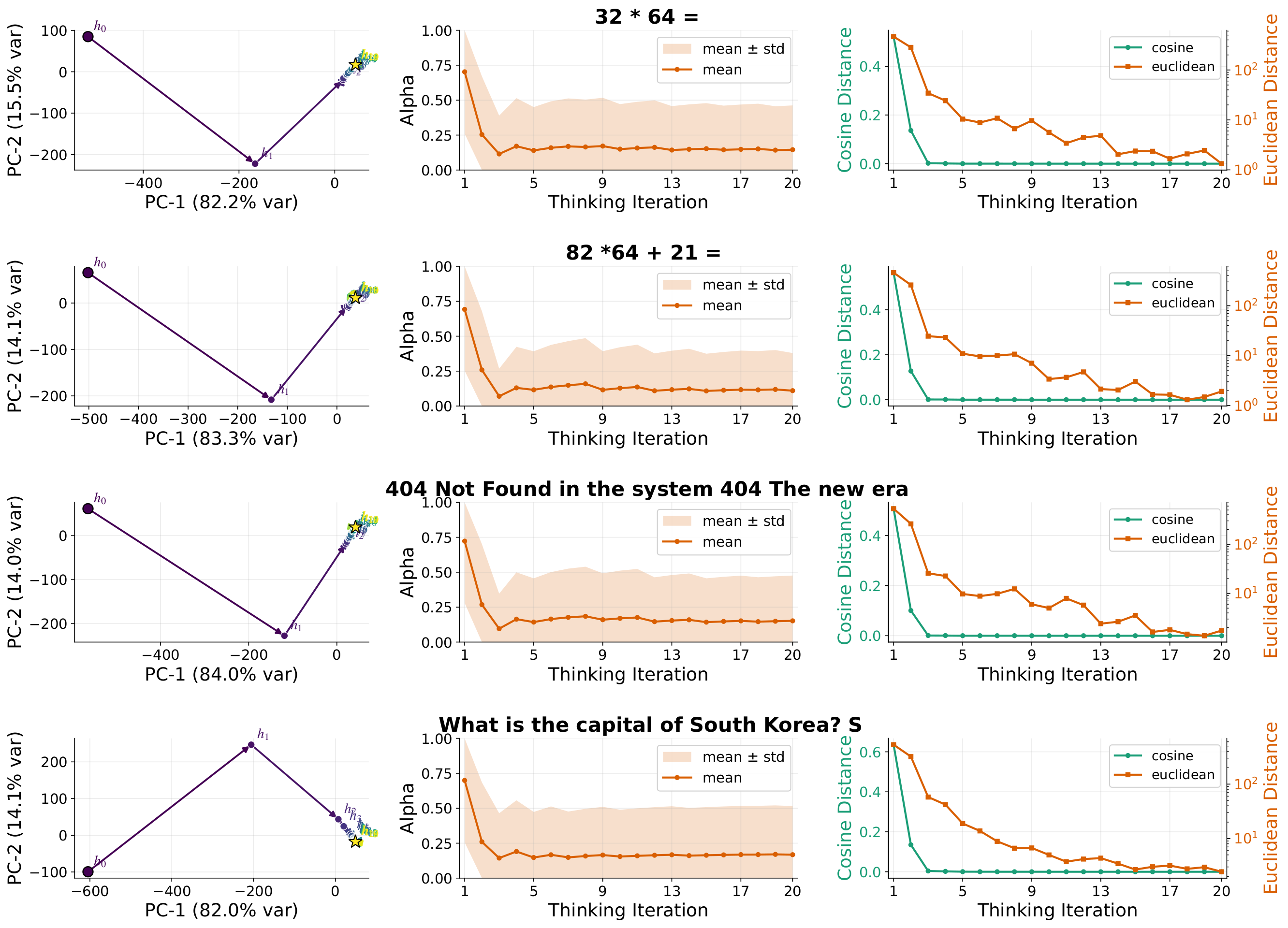
Figure 4: LoopUS quickly stabilizes latent reasoning trajectories. For representative Qwen4B examples, the PCA projection of hidden states shows a large early transition followed by compact refinement near the final answer, while the selective-gate coefficient and hidden-state distances rapidly contract over thinking iterations.

Figure 5: Token-level thinking traces reveal staged refinement. Example generations from Qwen4B show how LoopUS organizes reasoning across successive steps, progressively refining intermediate tokens before converging to the final response.
Video
GPU Sponsorship
We are always looking for GPU sponsorship. If you are interested, please contact. pthpark1@pusan.ac.kr